LP4.6: Lösen von Incidents und Service Requests

Prozessname: Lösen von Incidents und Service Requests - Teil von: Service-Lifecycle-Prozesse - Betreiben der Services
Nächster Prozess: Lösen von Problemen
Prozess-Beschreibung
Der Incident-Management-Prozess in YaSM (Abb. 1) ist für das Bearbeiten von Service Incidents (Meldungen vermuteter oder tatsächlicher Service-Unterbrechungen) oder Service Requests (Serviceaufträgen) verantwortlich. Im Falle von Incidents hat des Prozess das primäre Ziel, den Service für den Anwender so schnell wie möglich wieder herzustellen. In manchen Fällen wird dazu ein Workaround eingesetzt, falls die zugrundliegende Ursache nicht unmittelbar identifiziert und/ oder behoben werden kann.
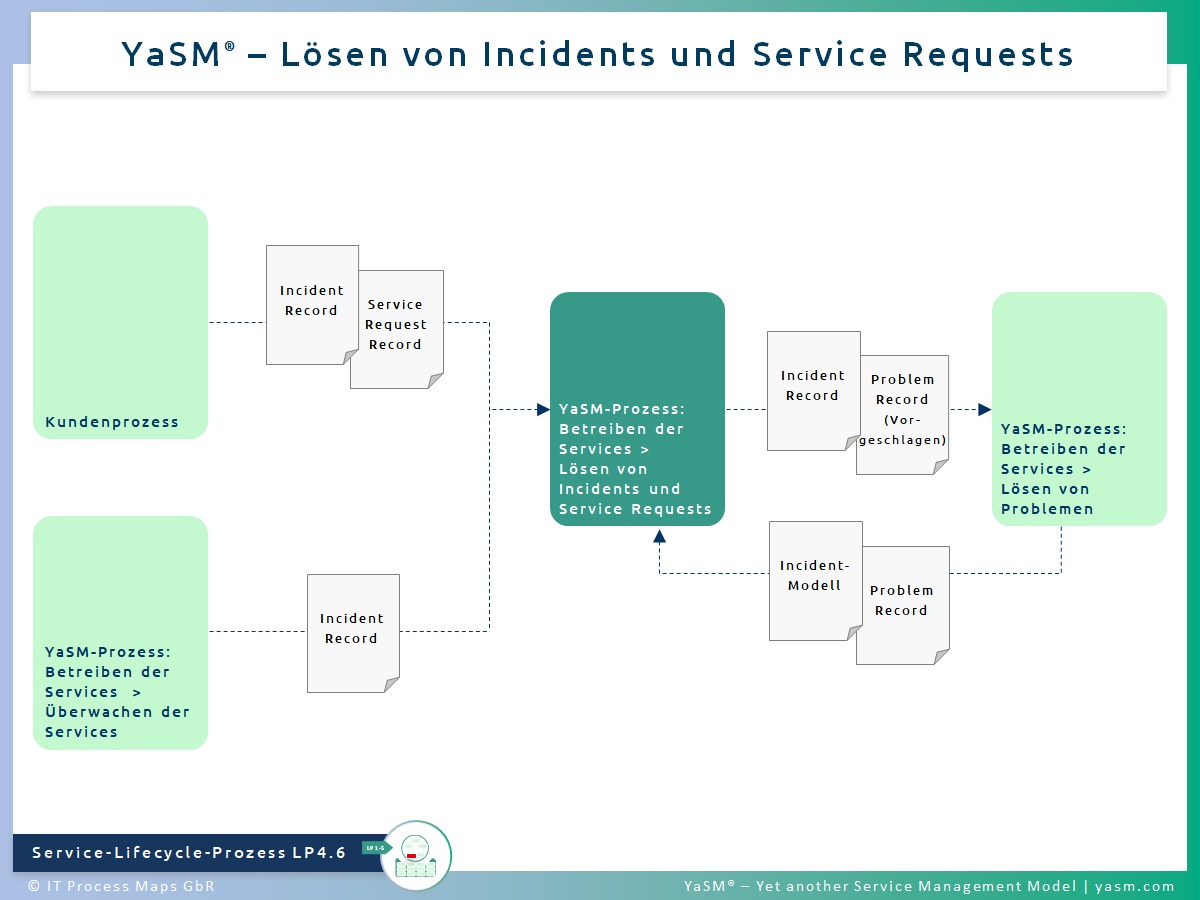
Der YaSM Incident-Management- und Service-Request-Management-Prozess ('LP4.6').
Kompatibilität: YaSM Incident-Management ist kompatibel mit ISO 20000, dem internationalen Service-Management-Standard (vgl. ISO/IEC 20000-1:2018, Abschnitt 8.6) und eignet sich zur Umsetzung der Practices 'ITIL 4 Incident Management', 'Service Desk' und 'ITIL 4 Service Request Management'.
Sub-Prozesse
YaSM's Incident-Management-Prozess beinhaltet die folgenden Sub-Prozesse:
- LP4.6.1: Unterstützen der Lösung von Incidents und Serviceaufträgen
- Prozessziel: Unterstützen der Bearbeitung von Incidents und Serviceaufträgen, z.B. durch Konfigurieren der Systeme, mit denen Incidents und Service Requests gemanagt werden und durch Bereitstellen einer Reihe von Incident- und Service-Request-Modellen.
- LP4.6.2: Erfassen von Incidents und Service Requests
- Prozessziel: Aufzeichnen aller relevanten Details von Incidents bzw. Service Requests. Überprüfen, ob alle erforderlichen Genehmigungen vorhanden sind, und Priorisieren der Incidents bzw. Serviceaufträge.
- LP4.6.3: Bearbeiten von Serviceaufträgen
- Prozessziel: Bearbeiten von Serviceaufträgen, bei denen es sich typischerweise um Anfragen nach Informationen oder Beauftragungen zur Implementierung von geringfügigen Changes (Standard-Changes) wie z.B. eines Passwort-Resets handelt.
- LP4.6.4: Proaktives Informieren von Benutzern und Kunden
- Prozessziel: Anwender über eingetretene oder vorhersehbare Service-Ausfälle informieren, sobald diese dem 1st Level Support bekannt werden, so dass die Anwender und Kunden in die Lage versetzt werden, sich auf Service-Unterbrechungen einzustellen. Dieser Prozess ist auch für das Verteilen anderer wichtiger Informationen zuständig, wie z.B. aktuelle Sicherheits-Warnungen.
- LP4.6.5: Lösen von Major Incidents
- Prozessziel: Lösen eines Major Incidents (schwerwiegenden Incidents). Major Incidents verursachen gravierende Unterbrechungen der Geschäftstätigkeiten und müssen mit höherer Dringlichkeit gelöst werden. Das Ziel besteht in der schnellen Wiederherstellung des Service, ggf. mit Hilfe eines Workarounds.
- LP4.6.6: Lösen von Incidents im 1st Level Support
- Prozessziel: Lösen eines Incidents innerhalb der vereinbarten Lösungszeit. Ziel ist die schnelle Wiederherstellung des Service ggf. durch Anwenden eines Workarounds. Sobald klar wird, dass der 1st Level Support den Incident nicht selbst lösen kann oder wenn die festgelegte Zeit für eine Lösung durch den 1st Level überschritten wird, wird der Incident an den 2nd Level Support übergeben.
- LP4.6.7: Lösen von Incidents im 2nd Level Support
- Prozessziel: Lösen eines Incidents (Service-Unterbrechung) innerhalb der vereinbarten Lösungszeit. Ziel ist die schnelle Wiederherstellung des Service ggf. mit Hilfe eines Workarounds. Falls erforderlich, können spezialisierte Support-Gruppen oder die Supplier (3rd Level Support) mit einbezogen werden.
- LP4.6.8: Überwachen von Incidents und Service Requests
- Prozessziel: Laufende Verfolgung des Bearbeitungsstands offener Incidents und Serviceaufträge, so dass Eskalationen und Gegenmaßnahmen eingeleitet werden können, falls die vereinbarten Lösungszeiten überschritten zu werden drohen.
- LP4.6.9: Schließen von Incidents und Service Requests
- Prozessziel: Durchführen einer abschließenden Qualitätskontrolle vor dem formalen Schließen der Incident bzw. Service Request Records. Das Ziel besteht darin, sicherzustellen, dass der Lösungsweg der Incidents oder Serviceaufträge in ausreichendem Detail dokumentiert ist. Zusätzlich sollen eventuelle Erkenntnisse aus der Lösung von Incidents für die weitere Nutzung dokumentiert werden.
Prozess-Outputs
Die folgenden Dokumente und Records werden vom Incident-Management-Prozess erzeugt. YaSM-Datenobjekte [*] sind mit einem Sternsymbol markiert, und andere Objekte werden in grau dargestellt.
- Änderungs-Vorschläge zu Informationen zur Selbsthilfe
- Ein Vorschlag zur Aktualisierung der Informationen für Anwender zur Selbsthilfe. Diese werden z.B. auf den Support-Seiten des Service-Providers im Intranet zur Verfügung gestellt.
- Beschwerde-Record
- Ein Record, der alle Einzelheiten einer Beschwerde von Kundenseite enthält, einschließlich der durchgeführten Aktivitäten zur Behandlung der Beschwerde. [*]
- Change Record
- In einem Change Record sind alle Einzelheiten eines Changes enthalten; er dokumentiert somit den Lebenszyklus eines einzelnen Changes. Zu Beginn beschreibt ein Change Record einen Change-Antrag (Request for Change, RFC), der vor der Implementierung des Changes zu bewerten und freizugeben ist. Weitere Informationen werden im Verlauf des Changes hinzugefügt. [*]
- CI Record
- Konfigurations-Information wird für alle Konfigurations-Elemente (Configuration Items, CIs) in CI Records gepflegt, die unter der Kontrolle des Konfigurations-Managers stehen. In diesem Zusammenhang gibt es unterschiedliche Typen von CIs: Anwendungen, Systeme und andere Infrastruktur-Komponenten werden als CIs behandelt, aber oft auch Services, Richtlinien, Projektdokumente, Mitarbeiter, Lieferanten usw. Konfigurations-Informationen sind im Konfigurations-Management-System (Configuration Management System, CMS) verzeichnet. [*]
- Fragebogen zur Kundenumfrage
- Eine Kundenumfrage setzt typischerweise Fragebögen ein, mit denen Einblick in die generelle Zufriedenheit der Kunden und zu speziellen (Aspekten von) Services aus Kundensicht gewonnen werden sollen. In vielen Fällen werden Antworten auf einer Skala gegeben, wie z.B. '1: Sehr unzufrieden', ... , '10: Sehr zufrieden'. [*]
- Incident- bzw. Request-Statusanfrage
- Eine Anfrage bezüglich des aktuellen Bearbeitungsstands eines Incidents bzw. Serviceauftrags; diese wird typischerweise von einem Anwender gestellt, der zuvor einen Incident bzw. Auftrag gemeldet hat und Verzögerungen erfährt.
- Incident Record
- Ein Datensatz mit allen Angaben zu einem Service Incident, in dem der Verlauf des Incidents von der Ersterfassung bis zur Schließung dokumentiert ist. Ein Service Incident ist definiert als ungeplante Unterbrechung oder Qualitätsminderung eines Service. Auch ein Ereignis, das in der Zukunft einen Service beeinträchtigen könnte, wird als Incident behandelt (z.B. der Ausfall einer Festplatte in einem Satz gespiegelter Festplatten). Siehe auch: Checkliste 'Incident Record'. [*]
- Incident-Modell
- Incident-Modelle enthalten die vordefinierten Schritte zum Umgang mit einem bestimmten Incident-Typ. Incident-Modelle dienen dem Zweck, wiederkehrende Incidents effektiv und effizient zu bearbeiten. [*]
- Informationen zum Change-Status
- Aktuelle Status-Informationen zur Implementierung eines Changes. Diese Informationen werden dem Change-Manager von den verschiedenen Prozessen zur Verfügung gestellt, die freigegebene Changes implementieren. Der Change-Manager wird so in die Lage versetzt, die Change Records und die Change-Planung aktuell zu halten.
- Infos für Anwender zur Selbsthilfe
- Informationen für Anwender zur Selbsthilfe. Diese werden z.B. auf den Support-Seiten des Service-Providers im Intranet zur Verfügung gestellt.
- Proaktive Anwender-Information
- Eine Meldung über bestehende oder potentielle Service-Unterbrechungen an die Anwender oder Kunden, damit die Anwender sich auf die zeitweilige Unterbrechung des Service einstellen können.
- Problem Record
- Ein Datensatz mit allen Angaben zu einem Problem, in dem der Verlauf des Problems von der Ersterfassung bis zur Schließung dokumentiert ist. Ein Problem ist definiert als die zugrundeliegende Ursache eines oder mehrerer (potentieller) Incidents, auch wenn die Ursache bei der Erstellung eines Problem Records oft noch nicht bekannt ist. In vielen Fällen wird eine Umgehungslösung (Workaround) für ein Problem bereitgestellt, solange eine vollständige Lösung noch nicht verfügbar ist. Siehe auch: Checkliste 'Problem Record'. [*]
- Service Request Record
- Ein Record, der alle Details eines Service Requests (Serviceauftrags) aufzeichnet. Service Requests sind formale Anfragen eines Kunden bzw. Anwenders im Rahmen bestehender Service-Vereinbarungen - z.B. nach Informationen, Beratung, Zurücksetzen eines Passworts, oder Installation einer Workstation für einen neuen Anwender. [*]
- Service-Request-Modell
- Service-Request-Modelle enthalten die vordefinierten Schritte zum Umgang mit einem bestimmten Typ von Serviceauftrag. Request-Modelle dienen dem Zweck, häufig wiederkehrende Serviceaufträge effektiv und effizient zu bearbeiten. [*]
- Statistik zur Service-Inanspruchnahme
- Statistische Daten zur Inanspruchnahme der Services durch Kunden bzw. Benutzer, als Basis für die Erstellung von Kunden-Rechnungen.
- Support-Anfrage
- Eine Anforderung zur Unterstützung bei der Behebung eines Incidents oder Problems. Eine solche Anforderung wird üblicherweise vom Incident- oder Problem-Manager gestellt, wenn weitere technische Expertise für die Behebung von Incidents oder Problems erforderlich ist.
- Vorschlag zur Verbesserung der Kontinuitäts-Vorkehrungen
- Ein Vorschlag zur Verbesserung der Service-Sicherheit. Solche Vorschläge können an jeder Stelle innerhalb der Organisation entstehen. [*]
- Vorschlag zur Prozess-Änderung
- Ein Vorschlag zur Änderung eines oder mehrerer Service-Management-Prozesse. Vorschläge für Prozess-Änderungen oder -Verbesserungen können an jeder Stelle innerhalb der Organisation entstehen.
- Vorschlag zur Service-Änderung
- Ein Vorschlag zur Änderung eines Service, z.B. zur Verbesserung der Qualität oder Wirtschaftlichkeit des Services. Solche Vorschläge können an jeder Stelle innerhalb oder außerhalb der Service-Provider-Organisation entstehen.
- Wiederherstellungs-Plan
- Wiederherstellungspläne (Recovery-Pläne) enthalten genaue Anweisungen zu den Maßnahmen, mit denen bestimmte Services und/ oder Systeme nach einem Ausfall wieder hergestellt werden können, was in vielen Fällen auch die Wiederherstellung von Daten zu einem definierten, konsistenten Stand mit einschließt. [*]
Anmerkungen:
[*] "YaSM-Datenobjekte" sind Dokumente und Records, für die YaSM detaillierte Empfehlungen bereithält: Für jedes YaSM-Objekt gibt es eine Checkliste (siehe Dokumentvorlage 'Incident Record' sowie weitere Beispiele), die die typischen Inhalte beschreibt, und ein Lifecycle-Diagramm, das darstellt, wie sich der Zustand des Objekts ändert, während es von verschiedenen YaSM-Prozessen erstellt, geändert, gelesen und archiviert wird (siehe Beispiel).
"Andere Objekte" sind eher informelle Daten oder Informationen. Es gibt aus diesem Grund keine zugehörigen Lifecycle-Diagramme oder Checklisten.
Prozess-Kennzahlen
Prozesskennzahlen werden benötigt, wenn gemessen werden soll, ob die Service-Management-Prozesse "zufriedenstellend" laufen.
Vorschläge zu geeigneten Prozess-Kennzahlen entnehmen Sie der Liste von Kennzahlen zum Incident-Lösungs-Prozess.
Rollen und Verantwortlichkeiten
Prozess-Owner: Der Incident-Manager ist verantwortlich für die effektive Durchführung des Prozesses zur Lösung von Incidents und führt das entsprechende Berichtswesen durch. Er ist die erste Eskalationsstufe für Incidents, falls diese nicht innerhalb der in den Service-Levels vereinbarten Zeiten gelöst werden können.
| YaSM-Rolle / Sub-Prozess | 1st-Level-Supp. | 2nd-Level-Supp. | Config.-Mgr. | Incident-Mgr. | Major-Incident-Team | Serv.-Owner | Bearb.-gruppe f. Serv.-auftr. | Techn.- Fachexp. | |
|---|---|---|---|---|---|---|---|---|---|
| LP4.6.1 | Unterstützen der Lösung von Incidents und Serviceaufträgen | - | - | - | AR | - | R | - | R |
| LP4.6.2 | Erfassen von Incidents und Service Requests | R | - | - | A | - | - | - | - |
| LP4.6.3 | Bearbeiten von Serviceaufträgen | R | - | - | A | - | - | R | - |
| LP4.6.4 | Proaktives Informieren von Benutzern und Kunden | R | - | - | A | - | - | - | - |
| LP4.6.5 | Lösen von Major Incidents | R | - | R | AR | R | - | - | - |
| LP4.6.6 | Lösen von Incidents im 1st-Level-Support | R | - | - | A | - | - | - | - |
| LP4.6.7 | Lösen von Incidents im 2nd-Level-Support | - | R | R | A | - | - | - | R |
| LP4.6.8 | Überwachen von Incidents und Service Requests | R | - | - | AR | - | - | - | - |
| LP4.6.9 | Schließen von Incidents und Service Requests | R | - | - | A | - | - | - | - |
Anmerkungen

Basiert auf: Der Incident-Management-Prozess aus der YaSM-Prozesslandkarte.
Von: Stefan Kempter ![]() und Andrea Kempter
und Andrea Kempter ![]() , IT Process Maps.
, IT Process Maps.
Video

In diesem Video mit Stefan Kempter erfahren Sie, aus welchem Grund Service-Provider mit Incidents und Serviceaufträgen professionell umgehen müssen.
Video ansehen: Guter Kunden-Support ist kein Zufall (10:41 Min.)
Themenverwandte Artikel

Die Betriebsprozesse - insbesondere Incident Management und Problem Management - sind wahrscheinlich die bekanntesten (und in der Praxis am häufigsten umgesetzten) ITSM-Prozesse.
[ ... Weiterlesen ]
Prozess-Beschreibung › Sub-Prozesse › Prozess-Outputs › Kennzahlen › Rollen





{kind=link}